
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 취득후기
- 01BFS
- COSPROJAVA1급
- 네트워크플로우
- 구현
- YBMCOS
- 다익스트라
- 백준
- 세그먼트트리
- 우선순위큐
- 재귀함수
- 시뮬레이션
- 이젠 골드구현도 어렵네..
- COSPRO
- 다이나믹프로그래밍
- 게더타운시작
- 백준코딩테스트
- deque
- 엘라스틱서치
- DFS
- QUICKSTARTGUIDE
- java
- spring
- PS
- GatherTown
- 완전탐색
- 자바PS
- dp
- 알고리즘
- BFS
- Today
- Total
공부공간
Web Crawling ) BeautifulSoup 다루기 본문
파이썬 버전 3.6 / beautifulsoup4 4.6.3 / requests 2.21.0
BeautifulSoup 은 http request로 얻어온 태그들을 유의미하게 파싱할수있는 라이브러리이다.
먼저 Requests 라이브러리는 특정 페이지에 html 정보를 string 형식으로
python으로 가져오는 기능을한다.
하지만 단순한 string에서 우리가 원하는 정보를 찾기 어렵기 때문에 BeautifulSoup을 이용한다.
예시를 통하여 알아보자.
requests 라이브러리는
!pip install requests를 통하여 간단하게 설치할 수있다.
예시로 네이버 증권 페이지에 html을 requests안에 get 사용하여 가져와 본다면
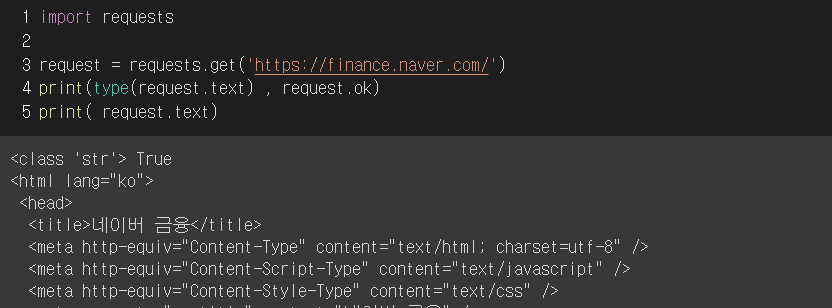
이러한 형식으로 출력이 된다. ( requests.get(url) )
보이는 것처럼 request의 type은 그냥 string이고 잘 가져왔는지의 여부를 request.ok로 찍어볼수있다.
그 아래에는 실제 네이버 증권 html을 구성하고 있는 페이지 소스이다.
개발자도구(F12)에서 보여지는 그대로를 가져온것이다.
하지만 우리는 특정 태그안의 정보들이 필요하므로 BeautifulSoup을 사용해 단순 string을 변형해보자

BeautifulSoup의 선언은
!pip install BeautifulSoup4 로 일단 설치를 해주자
BeautifulSoup4 뒤에 숫자는 버전이라고 생각해주면된다.
이후에
from bs4 import BeautifulSoup
를 통하여 BeautifulSoup을 임포트 시켜주자.
아까 requests.get으로 받았던 본문의 내용을 파싱을 해주는 선언을 하자.
BeautifulSoup(request.text , ' 사용할 파서')
를통하여 단순 string의 type이 바뀐것을 알수있다. 이제 원하는 태그에 접근하여서 정보를 가져오면 된다.
파서의 종류는 다양한데, lxml, htmlparser , html5lib 등이 있다.
( 파서에 대해서 궁금하면 https://www.crummy.com/software/BeautifulSoup/bs4/doc/ 을 참고하자)
즉 이후에는 bsoup.find 나 select 을 통하여 태그 정보에 접근하면된다.
여기서는 select로 예시를 가져와 보겠다.
bsoup.select( 태그의 위치 정보 )

페이지내에서 어떤 한 정보를 찾기 위해서 개발자 도구를 켜주자(F12)
많은 정보를 가지는 페이지일수록 여러 하이퍼링크로 연결되어있고, 페이지내의 소스도 복잡하다.
하지만 위 그림에서 화살표 모양의 버튼을 클릭하고 내가 원하는 부분으로 마우스를 오버하면 바로 그 태그정보를
html내에서 찾아준다. ( 정말 편한기능 / 추후 셀레니움에서도 사용한다 )
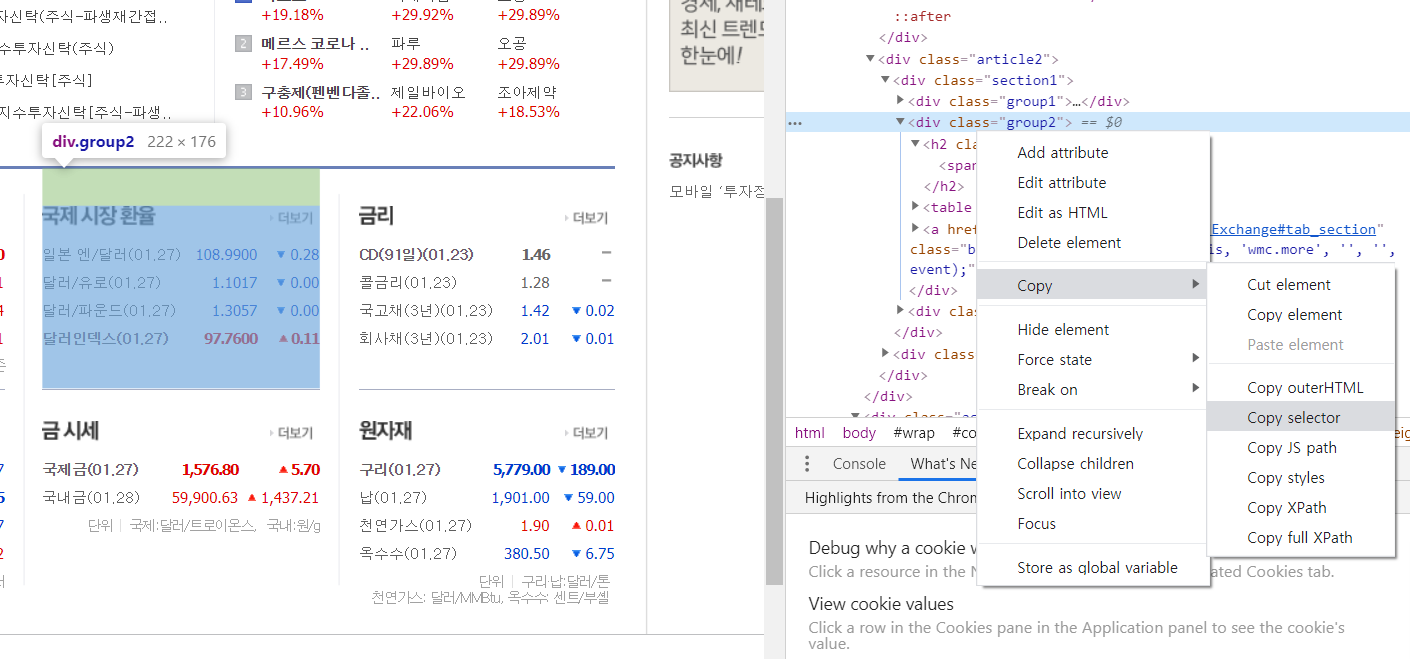
이후에 Copy selector를 이용하여 태그정보를 복사할수있다.
예시는 국제 시장환율에 있는 정보들을 가져와보겠다.

해당 selector에 대한 응답은 list 타입의 객체를 리턴받았다.
For 를 돌면서 list안에 어떠한요소가 있는지 확인해보자.
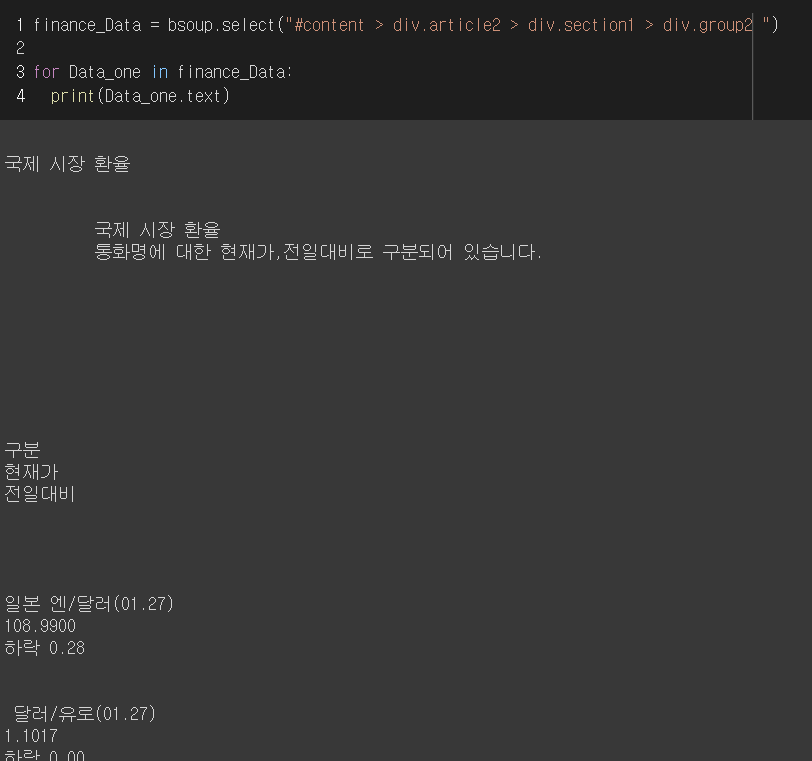
페이지내에서 원하는 정보는 잘 가져왔지만 공백이 너무많다.
공백을 제거하고 예쁘게 출력해보자.

위처럼 간단한 컴프리핸션과 인덱스 슬라이싱으로 내가 필요한 정보만 가져올수있다.
추후 이러한 정보들을 Pandas의 Dataframe이나 Series로 정리하면서
데이터를 다룰수있다.
질문과 태클은 환영입니다
'Natural Language Processing > Crawling' 카테고리의 다른 글
| ToyProject ) 내 주변 약국에는 마스크가 얼마나 남아있을까..? (5) | 2020.03.16 |
|---|---|
| Web Crawling ) 시작하기 전에.. (0) | 2020.01.27 |
